
Hadoop
Data se stala příležitostí a současně problémem každé společnosti. Výzkumník IDC předpověděl, že v roce 2014 se jejich množství bude více než zdvojnásobovat každé dva roky, přičemž v roce 2020 dosáhne hodnoty 44 bilionů gigabitů. Aby bylo možné toto množství uřídit, tak technologie vzniklé na začátku druhého tisíciletí ve firmách, jako je Google nebo Yahoo, se musí přemístit na nové trhy, které poptávají zpracování dat na webové úrovni.
Vstupte do Hadoop. Ačkoli existuje již několik let, okolní ekosystém vyrostl a mnoho velkých společností se zajímá, jakým způsobem by Hadoop mohl přispět k jejich podnikání. Korporátní včlenění zůstává stále na nízké úrovni, jak firmy dále prozkoumávají projekty, týkající se tématu „Big Data“. Ale jeho benefity a nevýhody představují významnou část diskuze CIO.
Nyní se blíže podíváme na Hadoop, co do jeho možností a limitací.
Co znamená Hadoop?
Hadoop představuje softwarový rámec, což znamená, že nabízí sadu funkcí, které mohou být uživateli přizpůsobovány. Je open-source - nikdo nevlastní danou technologii, a kdokoli ji může použít.
Na rozdíl od mnoha tradičních databází, které se spoléhají na monolitické systémy, které ukládají data do před definovaných sloupců a řádků, Hadoop je vytvořen pro práci s daty, která jsou distribuována napříč clustery nízko nákladového hardware, který může být škálován na základě potřeb uživatelů. Tato struktura umožňuje společnostem katalogizovat větší objem a pestřejší varianty dat a poté je efektivní cestou analyzovat.
Kde vznikl?
Hadoop začal v roce 2000, kdy inženýři Doug Cutting a Mike Cafarella vytvářeli open-source vyhledávač, nazvaný Nutch. Inspirováni několika výzkumnými dokumenty společnosti Google, si vypůjčili koncept distribučního systému pro soubory a MapReduce šablonu pro paralelní pracování, s cílem využít sílu počítačů, aby se Nutch mohl dále vylepšovat.
Společnost Yahoo najala p. Cuttinga na plný úvazek v roce 2006, přičemž on a jeho tým vylepšili software do bodu, kdy byl schopen zacházet s rozsáhlými dary a tisíci počítačových nódů. Pan Cutting nazval tuto technologii Hadoop po plyšákovi jeho syna - žlutém slonu.

Pan Doug Cutting a inspirace pro symbol Hadoop – plyšový slon jeho syna.
Jádro Hadoop: HFDS a MapReduce
Hadoop je tvořen dvěma hlavními komponenty: Hadoop Distributed File System (HDFS) a MapReduce.
HDFS řídí ukládání dat. Soubory jsou fragmentovány na menší bloky, které jsou distribuovány napříč systémem počítačů – clusterem. Počítače zapojené do clusteru se nazývají nódy.
Zatímco mnohé tradiční relační databáze ukládají data v předem definovaných sloupcích a řádcích, HDFS umožňuje ukládání narůstajícího množství nestrukturovaných dat, jako jsou například videa a sociální příspěvky. Některé společnosti využívají HDFS k vytvoření tzv. datových jezer, tedy obzvláště velkých shromáždišť dat, které analytika podporuje. Hadoop je též často využit spolu s tradičními databázemi.
Protože HDFS ukládá data zejména pro komoditní hardware než pro drahé a specializované stroje, je to obecně levnější a snazší využití. HDFS též vytváří kopii každého bloku a následně je distribuuje napříč clusterem, takže data nejsou ztracena, pokud dojde k selhání serveru. (Viz diagram níže.)
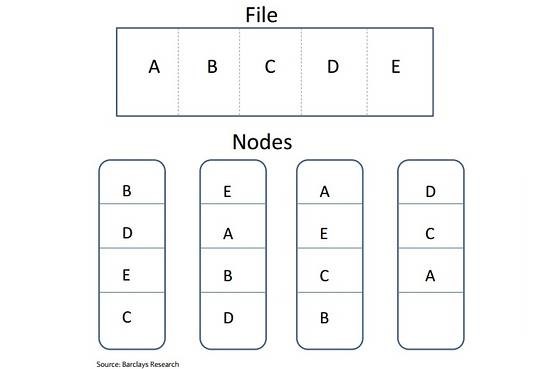
HDFS rozděluje rozsáhlé složky do bloků a distribuuje je / duplikuje napříč několika nódy v clusteru.
Kalkulace se děje simultánně v nódech v clusteru – tento přístup se nazývá paralelní zpracování. Rozložení práce může společnostem pomoci při řízení většího objemu dat v kratším čase.
MapReduce představuje programovací model pro analýzu dat v Hadoop. Má tři hlavní fáze: Mapování, Promíchání a Redukování.
První fáze sbírá vstupní data a připraví je na analýzu. Ve zprávě publikované firmou Barclays v březnu 2015 analytici osvětlují, jak může být Hadoop využit pro analýzu zákaznických nálad na sociálních médiích. Na začátku je mnoho syrového textu, Mapování jej pak rozčlení na několik různých skupin, určí náladu skrytou v daných slovech a přiřadí jim buď pozitivní, negativní nebo neutrální hodnotu.
Funkce Promíchání se zaměřuje na detailní analýzu těchto slov. Například u sociálních médií, Promíchání vyjme podstatu každého slova uskladněného v clusteru a složí je k sobě. Je to důležitý krok, protože data se šíří přes několik nódů v daném clusteru.
V třetím kroku – Redukování – jsou s daty prováděny kalkulace, tak, aby se uživatel dostal blíže k odpovědi na jeho otázku. V tomto případě, určí, jaké procento příspěvků v sociálních médiích bylo pozitivní, negativní nebo neutrální. Společnost může využít tento vhled týkající se zákazníků a na jeho základě upravit svou marketingovou strategii.
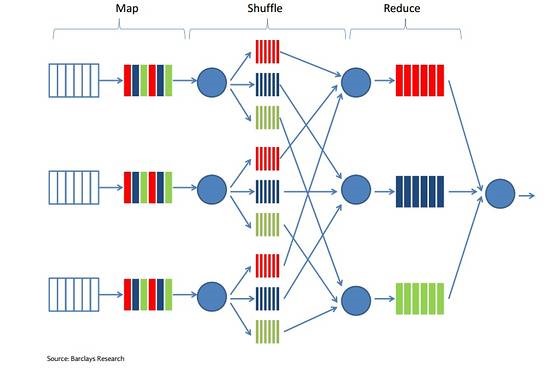
Příklad MapReduce analýzy nálady na sociálních médiích dle jednotlivých fází – barvy představují nálady, kruhy symbolizují nódy.
YARN, zkratka pro anglické Yet Another Resource Negotiator, představuje třetí komponent, který je považovaný za klíčovou součást Hadoop. Vytváří rozvrh pro zpracování dat a řídí výpočetní zdroje, které jsou z vnějšku clusteru.
Hadoop ve firmě
Ve velkých firmách, Hadoop je obvykle umístěn u datového skladu, který shromažďuje informace z celé firmy, ze všech oddělení a následně využívá sadu komplexních pravidel pro jejich analýzu a řízení pro business reporty. Hadoop je často využíván pro management nestrukturovaných dat, která se zatím nehodí do datového skladu. Též může být užitečný pro analýzu informací, které zatím nemají jasný podnikatelský záměr.
Hadoop ekosystém
Na vývoj Hadoop dohlíží Apache Software Foundation, nezisková organizace, která podporuje více než 350 open-source projektů. Jak jednotlivci, tak společnosti přispěli k těmto projektům a vytvořili jak open-source, tak ziskové nástroje jako je Hadoop. Projekt Apache Hive vyvinul databázový jazyk nazvaný HiveQL, který je podobný SQL, známému databázovému jazyku využívanému v mnoha společnostech. Projekt Apache Pig poskytuje jazyk – Pig Latin – jehož účelem je zjednodušit aktivity na MapReduce, na které je obecně nahlíženo jako na složité. A projekt Apache Sqoop usnadňuje pohyb dat mezi Hadoop a relačními databázemi. Pro více informací o Apache projektech klikněte zde.
Některé společnosti se snaží vytvořit verzi Hadoop systému využitelnou pro korporátní zákazníky, která vychází z ideí Hortonworks Inc. (zveřejněná v prosinci roku 2014), dále z Cloudera Inc. a MapR Technologies. Pan Cutting nyní pracuje ve firmě Cloudera.
Spark
Spark představuje Apache projekt, který zajímá zejména společnosti, které potřebují analyzovat velké objemy dat v reálném čase. Místo zapisování výstupu každé analýzy na disk, Spark shromažďuje výsledky uvnitř RDD (Resilient Distributed Datasets), které jsou uskladněny v dostupné paměti. To snižuje délku prodlevy a zvyšuje výkonnost. Mnoho oponentů říká, že Spark procesní engine je mnohem efektivnější než MapReduce. Experti na Big Data tvrdí, že MapReduce může být nepraktické a těžké na učení, což jsou dva faktory, které mohou zpomalit korporátní osvojení a pobídnout vývoj nových a lepších nástrojů.
„V blízké budoucnosti Spark pravděpodobně předstihne MapReduce jako všeobecný engine pro Hadoop,“ říkají výzkumníci z Barclays v březnové zprávě. Společnost IBM řekla, že v červnu včlení Spark do svých analytických a komerčních platforem.
Korporátní osvojení
Výzkumná společnost Gartner Inc. říká, že osvojení Hadoop stále zůstává na nízké úrovni, a to proto, že firmy mají problém s vyčíslením podnikatelské hodnoty Hadoop a též z toho důvodu, že je nedostatek pracovníků, kteří jsou schopni jej používat. Květnový průzkum, kterého se zúčastnilo na 284 globálních IT firem a též významné společnosti z dalších odvětví, ukazuje, že více než polovina z oslovených neplánuje do Hadoop investovat. Dle analytika Raimo Lenschowa z firmy Barclays by využití Hadoop mohlo vzrůst s využitím nástrojů, založených na SQL, tedy databázovém jazyce, který IT oddělení firem znají velmi dobře.
Rozšiřování Hadoop ve firmách by též mohlo pomoci, pokud by významní poskytovatelé technologií zajistili jeho integraci a podporu. Například: SE HANA od společnosti SAP kombinuje vnitro paměťovou databázi, pokročilou analytiku a integraci do datových úložišť, včetně Hadoop. Dále, firma Oracle nabízí integraci Hadoop, stejně jako jeho využitelnost na Big Data. Společnost Microsoft poskytuje Hadoop jako řízenou cloud službu na jejich platformě Azure a firma International Business Maschines nabízí Hadoop jako takový. Některé firmy nabízí bezpečnostní a další zajímavé vlastnosti pro podnikatele. Amazon Web Services společnosti Amazon prodává službu s názvem Elastic MapReduce, která je založená na Hadoop, která poskytuje řiditelný rámec pro management rozsáhlých množství firemních dat.
Za hranici Hadoop
Hadoop představuje jednu z mnoha datových technologií, které jsou dostupné na dnešním trhu. Například firma Facebook vyvinula open source SQL databázový engine s názvem Presto, s cílem řídit analytiku ve vlastním Big Data prostředí. Má vlastní rozhraní a přizpůsobitelný databázový engine. Jak řekla mluvčí společnosti Facebook, tak společnosti, jako je například Airbnb nebo Netfix, presto využívají.
Hadoop má své limity. Představuje jednu z mnoha datových technologií v rámci firmy. Je ale potřeba aby společnosti pochopily, že jsou to právě data z mobilních zařízení, sociálních médií a propojených zařízení, která redefinují jejich podnikání.
Zdroj: CIO Journal